Conventions
Signposting the Scholarly Web
This page provides an overview of a variety of conventions that are used by specifications on the Signposting site.
A Scholarly Object on the Web
- A persistent identifier, e.g. a DOI or handle expressed as an HTTP URI.
- A landing page that is reachable by dereferencing the persistent identifier and following HTTP redirects. The landing page typically describes the scholarly object and provides links to its content resources. In some cases, such as articles published in HTML, the landing page actually represents content of the resource. For simplicity, this is still referred to as the landing page. Essentially, Signposting uses the term landing page for the resource to which the object's persistent identifier resolves.
- One or more content resources that provide the actual content of the scholarly object, such as a PDF article, a CSV dataset, a ZIPped software repository, a dynamically generated map.
- One or more metadata resources that describe the scholarly object in commonly used formats.
- Other identifiers that pertain to the scholarly object, including:
- Identifiers for authors, e.g. ORCID or ISNI, expressed as HTTP URIs.
- Identifiers of applicable licenses, e.g. Creative Commons licenses expressed as HTTP URIs, preferably using SPDX license URIs.
- Identifiers for scholarly object types expressed as HTTP URIs from commonly used vocabularies, e.g. schema.org.
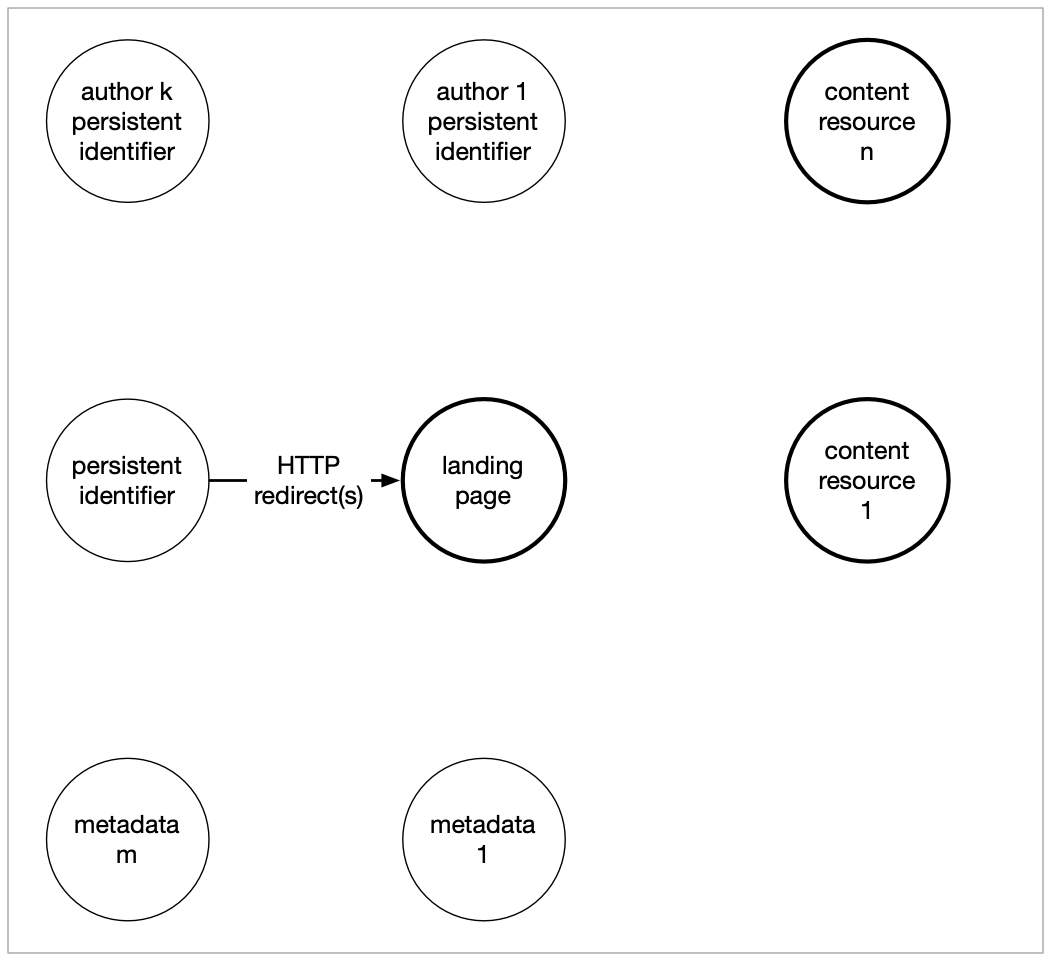
Signposting Modeling of a Scholarly Object on the Web
- The landing page, i.e. the resource to which the scholarly object's persistent identifier resolves, takes center stage in the approach. Since landing pages are under control of the custodians of scholarly objects, the approach is not dependent on technical interventions by parties other than those custodians, e.g. repository managers.
-
Links with specific link relation types point from the landing page to various resources that are constituents
of the scholarly object, e.g.
itemlinks point at content resources,describedbylinks point at metadata resources, etc. Modeling purists are known to have taken some issue with these links emanating from the landing page, rather than from the persistent identifier of the scholarly object. This choice is justified in two ways. First, it puts custodians of scholarly objects (repository managers) in the driver seat to make the required technical interventions without dependency on external parties. Second, the approach entails an equivalence between the landing page URI and the persistent identifier URI because:-
The persistent identifier URI redirects with an
HTTP 302 Foundto the landing page URI. In natural language, this technical approach translates to "You are looking for the resource identified by the persistent identifier URI. It's not here. But you can find it at the landing page URI." -
The landing page URI links to the persistent identifier URI with the
cite-aslink relation type. In natural language, this technical approach translates, to "In case you want to reference the landing page, don't do so using the landing page URI. Use the persistent identifier URI instead.
-
The persistent identifier URI redirects with an
-
In order to link from the landing page to content resources, the landing page is modeled as a collection.
This allows using links with the
itemrelation type to point from the landing page to content resources, and the inversecollectionrelation type to point back from content resources to the landing page.
Relation Types for Typed Links
Relation Types are generally registered in the IANA Link Relation Registry, which also describes their meaning and links to the specification in which they were originally defined. The Relation Types used for Signposting are listed below, with reference to the pattern in which they are applied.
| Relation Type | Signposting Pattern | Description |
author |
Author | The target of the link is a URI for an author of the resource that is the origin of the link. |
cite-as |
Identifier | The target of the link is a persistent URI for the resource that is the origin of the link. When accessing the persistent URI, it redirects to that origin resource. |
describedby |
Metadata Resources | The target of the link provides metadata that describes the resource that is the origin of the link. |
describes |
Metadata Resources | The origin of the link is a resource that provides metadata that describes the resource that is the target of the link. It is the inverse of the describedby relation type. |
type |
Type | The target of the link is the URI for a class of resources to which the resource that is the origin of the link belongs. |
license |
License | The target of the link is the URI of a license that applies to the resource that is the origin of the link. |
item |
Content Resources | The origin of the link is a collection of resources and the target of the link is a resource that belongs to that collection.
It is the inverse of the collection relation type. In Signposting, the landing page of a scholarly object is modeled
as a collection of content resources.
|
collection |
Content Resources | The origin of the link is a resource that belongs to a collection and the target of the link is the collection to which it belongs.
It is the inverse of the item relation type. In Signposting, the landing page of a scholarly object is modeled
as a collection of content resources. |
Attributes for Typed Links
There is currently no official registry for attributes that can be used on Typed Links. The most common ones are listed in the Web Linking RFC. The attributes that are important for Signposting are listed below, with reference to the pattern in which they are applied.
| Attribute | Signposting Pattern | Description |
type |
Metadata Resources, Content Resources | The value of the type attribute conveys the MIME type of the resource
that is the target of the link on which the attribute is used. |
profile |
Metadata Resources, Content Resources | The value of the profile attribute indicates the profile to which the resource that is the
target of the link conforms. Generally, a profile is a syntactic and/or semantic constraint that
applies beyond what can be expressed using the MIME type of the resource.
The profile attribute is, for example, useful when different
metadata resources have the
same MIME type (e.g. application/xml) but conform to a different schema.
The value of the profile attribute is a URI
that uniquely identifies the format (e.g. XML Schema URI). Note that the use of the profile attribute is standardized for certain MIME types, such as
application/ld+json. It is not for many others, including text/plain,
application/xml, and application/json and, as such, its use is a community convention introduced for Signposting.
|
Bibliographic Metadata Formats
Currently, there are no MIME types registered to unambiguously identify bibliographic metadata formats
that are commonly used in scholarly communication. And several unregistered MIME types are used to
refer to the same format. For example,
BibTeX is referred to by means of application/x-bibtex, application/force-download, and text/plain.
RIS is referred to by means of application/x-research-info-systems, application/force-download,
and text/plain.
Preferably, MIME types for bibliographic metadata formats should be
registered.
But CrossRef, DataCite, and mEDRA have established an interoperable
practice to access bibliographic metadata using content negotiation on the basis
of unregistered MIME types for three formats. Since Signposting is all about
pragmatism it uses these de-facto MIME types for interoperability; they are listed in the below table.
These MIME types are used in describedby links that point to bibliographic metadata resources
and should be expressed by a client in the Accept HTTP Request header when accessing the URI that is the target
of a describedby link.
| Bibliographic Metadata Format | MIME Type | |
| BibTeX | application/x-bibtex |
|
| CiteProc JSON | application/vnd.citationstyles.csl+json |
|
| RIS | application/x-research-info-systems |
Many other bibliographic formats are in use and many share text/plain,
application/xml, application/json, or application/ld+json as MIME types. In order to distinguish between
bibliographic formats that have the same MIME type, either a dedicated MIME type should be registered
or a profile attribute
can be used on a describedby link to clarify the metadata format beyond its MIME type. The former allows for content negotiation, the latter does not. The below table shows how the profile
approach can be used for popular XML-based formats. Note that the use of the profile attribute is standardized for some MIME types, such as
application/ld+json. It is not for many others, including text/plain,
application/xml, and application/json and, as such, it is a community convention introduced for Signposting.
| Bibliographic Metadata Format | type Attribute Value |
profile Attribute Value |
| MARC XML | application/xml |
http://www.loc.gov/MARC21/slim |
| MODS | application/xml |
http://www.loc.gov/mods/ |
| Simple Dublin Core | application/xml |
http://purl.org/dc/elements/1.1/ |
| Qualified Dublin Core | application/xml |
http://dublincore.org/documents/dcmi-terms/ |
| Rioxx version 3 | application/xml |
http://www.rioxx.net/schema/v3.0/rioxx/ |